Pythonでニューラルネットを実装する
「Pythonで多層パーセプトロンを実装する」では、多層パーセプトロンによってXOR関数を近似しましたが、重みや閾値などのパラメータは自分で決めていました。そこで今回は誤差逆伝播法を使ったニューラルネットワークを実装することでパラメータを自動で学習させてみます。
パーセプトロンとの違い
パーセプトロンもニューラルネットワークも脳の神経細胞が行う情報処理の仕組みを模倣したものであることは同じですが、ニューラルネットワークには以下のようなパーセプトロンとは異なる特徴があります。
特徴
- 出力が2値でない
- 活性化関数がステップ関数でない
- 損失関数
活性化関数
パーセプトロンでは、ニューロンが発火するかどうかは閾値によって決められ、出力される値は
か
のどちらかでした。しかしニューラルネットワークでは活性化関数というものを導入することでより複雑な発火の表現ができるようになっています。つまり活性化関数はニューロンがどのように発火するかを決めている関数といえます。活性化関数には種類があり、代表的なものでは以下の3種類があります。
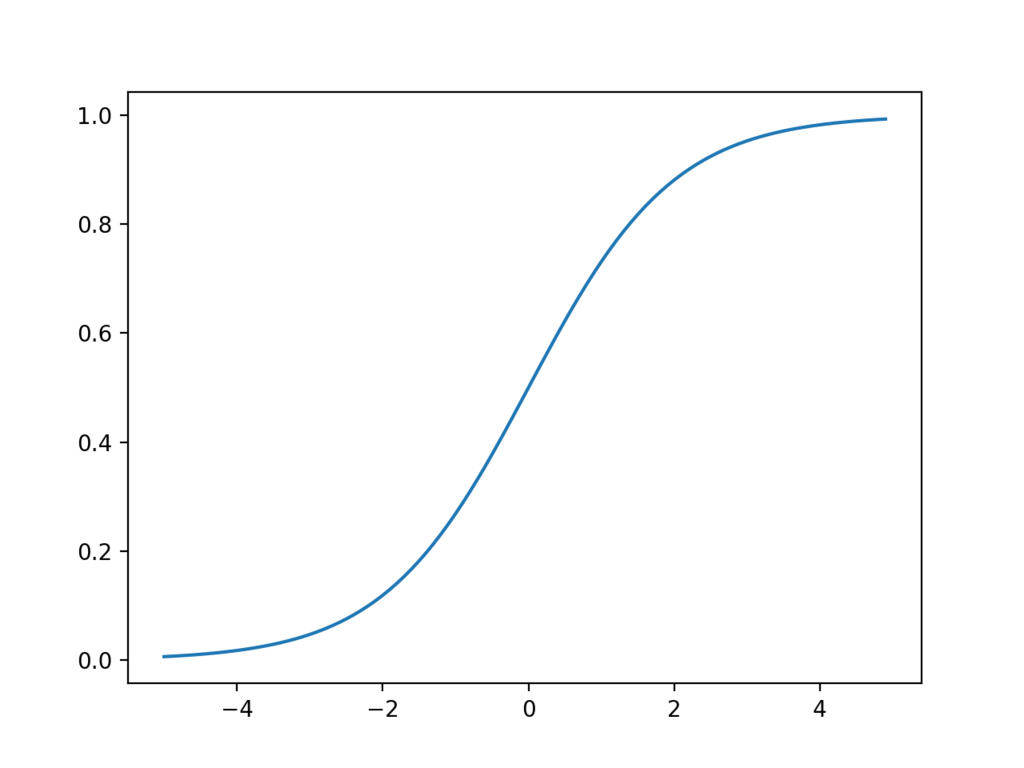
シグモイド関数
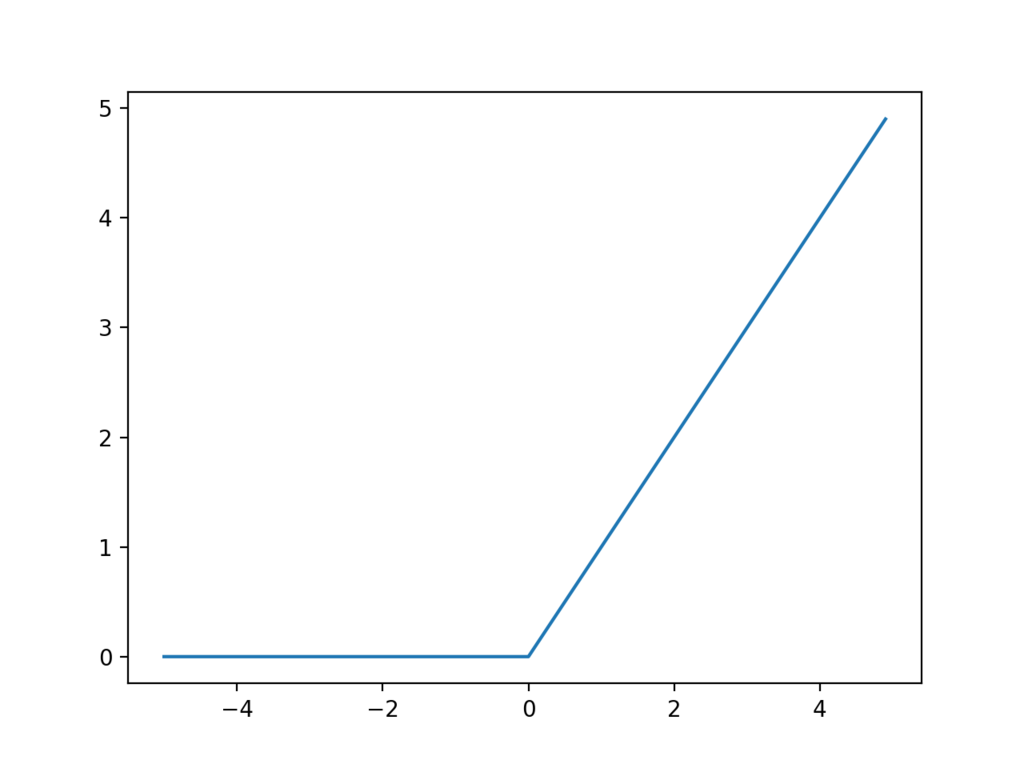
ReLU関数
tanh
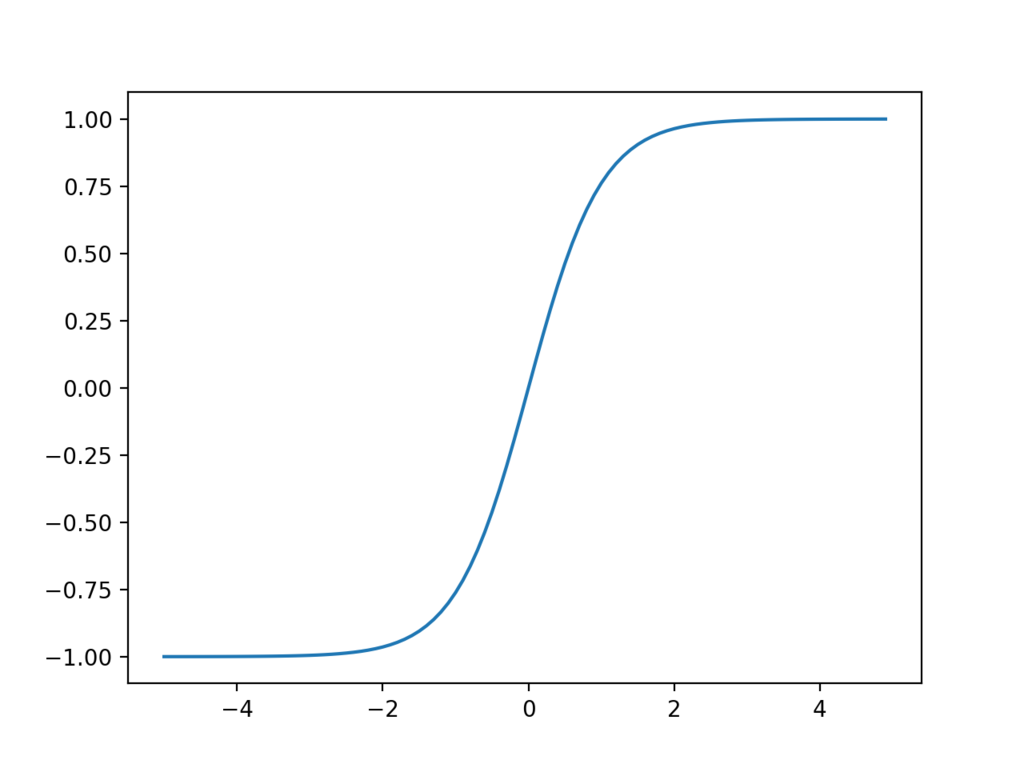
シグモイド関数やReLUは微分計算が簡単であることから広く使われています。tanhはRNNやLSTMなどの再帰型ニューラルネットによく使われます。
損失関数
損失関数とは、ニューラルネットワークの出力が正解データからどれだけ離れているか(誤差)を計算する関数です。一般的に回帰問題では2乗和誤差、分類問題ではクロスエントロピー誤差が用いられます。
2乗和誤差
クロスエントロピー誤差
ニューラルネットワークの順伝播
ニューラルネットを実装するにあたり、まず順伝播の計算式を導出します。今回は以下のような構造のネットワークを考えます。
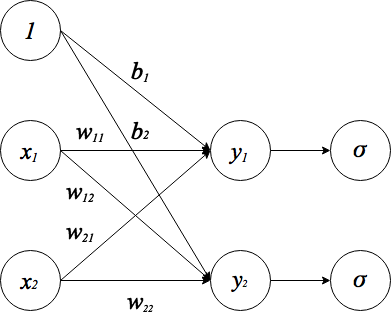
順伝播の流れを分かりやすくするために活性化関数()を明示的に書きました。
は入力信号、
は重み、
は出力信号を表しています。
はバイアスと呼ばれるもので、入力信号
と重み
をかけたものにこのバイアスを加えることで前回のエントリでいう閾値
と同じ役割を果たします。図では、バイアス項を加える処理を、入力
に
をかけるという処理で表しています。以上のことを踏まえると、まず活性化関数の手前までの計算は次のように表せます。
バイアス項が加わっただけで後はパーセプトロンの計算と変わりありません。 また、上の式はベクトルと行列を用いて一つの式にまとめることが出来ます。
ベクトルや行列を使って表すことで、プログラムに落とし込むときに線形代数のライブラリを活用でき、さらに一つの式にまとめることで入力や出力の数がどんなに多くなっても一層分の順伝播の計算は一回の計算で行えるようになります。ここで、
とすれば、上の式は
と非常に簡単な式になります。この計算は線形変換と呼ばれます。よって活性化関数を含めたこのニューラルネットワーク全体の順伝播の式は、
となります。さらに学習時には上の出力が損失関数に入力として与えられ、例えば2乗誤差を使う場合、
が誤差として出てきます。そしてこの誤差
から各パラメータ(重みやバイアスなど)に対する微分を効率的に計算するアルゴリズムが次に説明する誤差逆伝播法です。
誤差逆伝播法
ニューラルネットワークを学習させるにあたり、ニューラルネットワークが出力した誤差をもとに各パラメータをどれだけ修正するかを求める必要があります。この修正量は「あるパラメータを一定量変化させたときの誤差の変化量」と言い換えることができ、それは誤差に対する各パラメータの微分で表せます。この微分値を効率良く計算するアルゴリズムが誤差逆伝播法で、その原理の基本は連鎖律によって説明できます。
では上の順伝播計算で得た誤差から、学習すべきパラメータの誤差に対する微分を求めてみます。誤差逆伝播法では、出力層から逆順に誤差が伝播していくため、今回のネットワーク構造の場合は損失関数 -> 活性化関数 -> 線形変換の順に誤差が伝わっていきます。
損失関数の逆伝播
損失関数では学習するパラメータはありませんが後ろの層に誤差を伝えるため、を計算する必要があります。今回は損失関数に2乗和誤差を用いるので
は以下のようにして求められます。
これと順伝播の式を合わせて損失関数をPythonで書いてみます。
活性化関数の逆伝播
活性化関数についても同様に、学習すべきパラメータは無いので単純に誤差を入力信号で微分して後ろの層へ伝播させるだけです。今回はシグモイド関数とReLUを使います。まずシグモイド関数を微分してみると、
まとめると、
と導関数をシグモイド関数自身で表せます。これは重要な性質で、微分の計算をするときに順伝播で求めた値を再利用できるということです。Pythonによるシグモイド関数の実装は以下のようになります。
次にReLUの逆伝播を考えます。ReLUの微分はとても簡単です。
Pythonでの実装はこちらのリポジトリが参考になりました。
線形変換の逆伝播
線形変換では、重みとバイアス
の2つの学習パラメータがあります。そのため
,
を求めます。当然後ろの層へ誤差を伝えるために
も求めます。
また、微分の計算を分かりやすくするために、図のように線形変換を計算グラフで表します。
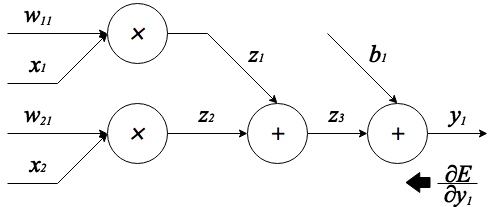
上の図は式 を表しています。さらに、上の式の計算途中の中間値を以下のように保存しておきます。
まず例として、出力から逆にたどって誤差に対する成分の微分を計算します。すると
は連鎖律を用いて、
と書けます。ここで、加算の部分は前の層から伝わってきた誤差をそのまま次の層に渡し、乗算の部分は入力信号をひっくり返したものを伝播させるので、
となります。他の成分も同様に誤差に対する微分を求めると、
となります。
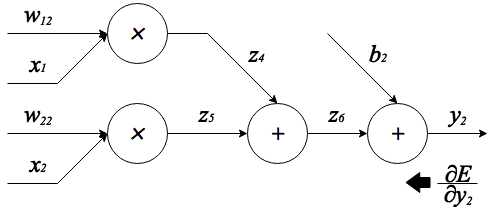
また、上の計算グラフは式 を表しており、計算途中の値は以下のように保存します。
これも先ほどと同様に誤差に対する各成分の微分を求めると、
これで誤差に対する全ての成分の微分が計算出来たのでそれらをまとめます。
すなわち、
したがってPythonでの実装は次のようになります。
勾配法
誤差逆伝播法によって各パラメータをどれだけ修正すれば良いか分かったので、次は実際にパラメータを調整してニューラルネットワークを学習させていきますが、その際に勾配法というアルゴリズムを使ってパラメータの値を更新していきます。勾配法(この場合は勾配降下法)では、損失関数の出力を最小にするために損失関数の勾配を活用します。具体的には、損失関数の勾配が小さくなる方へ進むことで損失関数の最小値を探します。式で表すと以下のようになります。
パラメータの更新式
上が重みパラメータ、下がバイアスパラメータの更新を行う式です。式中のは学習率というもので、誤差逆伝播法で得た修正量をどれだけ反映するか(どれだけパラメータを更新するか)を調整する係数です。Pythonで実装すると、以下のようになります。
今回実装するネットワークでは学習パラメータが存在するのは線形変換の部分のみなのでシグモイド関数やReLUでは何もしません。
実装
実装するのに必要な式が一通り表せたので、いよいよPythonでニューラルネットを実装します。今回もXOR関数を学習させてみます。まず以下のようにニューラルネットを訓練するクラスを書きました。
nnetモジュールには今までに書いた線形変換や活性化関数などのクラスがまとめてあります。また、上の訓練クラスを使ってXORの学習を行うコードスニペットの一例を以下にのせます。
さらに、学習したモデルを使って推論を行うスクリプトを作成しました。
上のコードでニューラルネットワークを訓練した結果、以下のようにXOR関数をうまく学習できました。
$ ./xor_predict.py ./xor_sample_weight.pkl in: [ 0. 0.] -> out: 0 (0.00486784050737) in: [ 0. 1.] -> out: 1 (0.997805826021) in: [ 1. 0.] -> out: 1 (0.997805828447) in: [ 1. 1.] -> out: 0 (0.00486784050737) $
今回作ったプログラムは以下のリポジトリに置いてあります。 github.com